Hierarchical Linear Models (HLM) / Multilevel Modeling Training Course
Hierarchical Linear Models (HLM) Multilevel Modeling Training Course is a specialized program designed for data professionals, researchers, and social scientists looking to master the complexities of analyzing nested data structures.
Skills Covered
Course Overview
Hierarchical Linear Models (HLM) Multilevel Modeling Training Course
Introduction
Hierarchical Linear Models (HLM) Multilevel Modeling Training Course is a specialized program designed for data professionals, researchers, and social scientists looking to master the complexities of analyzing nested data structures. As data becomes increasingly multilevel and longitudinal in nature, understanding and applying HLM is critical for robust statistical analysis. This course bridges theoretical understanding with practical applications, empowering participants to confidently run, interpret, and visualize multilevel models across diverse research settings.
Whether you're working in education, healthcare, public policy, or behavioral sciences, this course leverages real-world case studies and modern statistical software to build competence in multilevel regression modeling, random effects analysis, and cross-level interaction testing. It is ideal for professionals aiming to produce reproducible, policy-relevant, and peer-reviewed quality research using advanced statistical modeling techniques.
Course Objectives
- Understand the foundational principles of hierarchical linear modeling and its applications.
- Identify and analyze nested data structures and justify the use of HLM.
- Apply multilevel statistical models to longitudinal and cross-sectional data.
- Differentiate between fixed and random effects in multilevel models.
- Interpret model output using statistical software like HLM7, R, SPSS, and Stata.
- Conduct variance partitioning and intraclass correlation analysis (ICC).
- Model growth trajectories in longitudinal datasets.
- Handle missing data in multilevel modeling effectively.
- Utilize cross-level interactions to evaluate moderation effects.
- Report and visualize HLM findings using data storytelling techniques.
- Critically evaluate published literature using HLM methods.
- Develop, test, and compare nested model structures.
- Create replicable and ethical research frameworks using HLM.
Target Audiences
- Educational researchers
- Public health analysts
- Social science scholars
- Policy evaluators
- Econometricians
- Medical researchers
- Graduate students in quantitative fields
- Institutional data analysts
Course Duration: 10 days
Course Modules
Module 1: Introduction to Multilevel Modeling
- Overview of nested data
- Difference between OLS and HLM
- Rationale for multilevel analysis
- Real-world applications
- Intro to software interfaces
- Case Study: School performance across districts
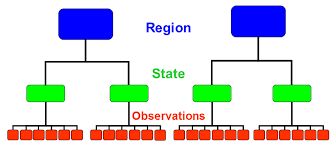
Module 2: Understanding Hierarchical Data Structures
- What defines hierarchy?
- Three-level and two-level models
- Unit of analysis decisions
- Data preparation essentials
- Variables classification (within vs. between)
- Case Study: Employee engagement in multinational firms
Module 3: Variance Partitioning & ICC
- Concept of variance components
- Calculating ICC
- Interpretation in applied contexts
- Visual tools for partitioning
- Importance in model selection
- Case Study: Classroom-level academic performance
Module 4: Random Intercepts and Slopes
- When to use random intercepts
- Adding random slopes
- Random coefficient modeling
- Interpretation of variance terms
- Diagnostics and goodness of fit
- Case Study: Patient satisfaction across hospitals
Module 5: Model Estimation Techniques
- ML and REML explained
- Stepwise model building
- Convergence issues
- Software estimation comparison
- Optimization strategies
- Case Study: Reading improvement interventions
Module 6: Cross-Level Interactions
- Concept of moderation across levels
- Creating interaction terms
- Visualization of interactions
- Interpretation challenges
- Application in behavioral sciences
- Case Study: Leadership impact on team performance
Module 7: Longitudinal Modeling
- Introduction to growth modeling
- Time as a level-1 predictor
- Centering time variables
- Handling autocorrelation
- Visualizing growth trajectories
- Case Study: Student motivation over school years
Module 8: Model Fit and Diagnostics
- Comparing nested models
- AIC, BIC, and deviance stats
- Residual plots
- Checking assumptions
- Addressing outliers
- Case Study: Stress level predictors in workplaces
Module 9: Dealing with Missing Data
- Types of missingness
- Multiple imputation strategies
- Software-specific handling
- Impact on model estimates
- Sensitivity testing
- Case Study: Attendance trends in primary schools
Module 10: Data Preparation for HLM
- Structuring multilevel datasets
- Aggregating data appropriately
- Dummy coding and centering
- Missing data imputation
- Validating data assumptions
- Case Study: Organizational change readiness
Module 11: HLM in R and Stata
- Setting up RStudio/Stata for HLM
- Script writing for multilevel models
- Plotting results
- Troubleshooting syntax errors
- Exporting results for reports
- Case Study: Health intervention impact evaluation
Module 12: Reporting and Visualization
- APA style reporting
- Graphical representation tools
- Summary tables and charts
- Highlighting model implications
- Policy communication
- Case Study: Teacher training outcomes
Module 13: Ethics in Multilevel Research
- Consent and data privacy
- Avoiding overfitting
- Transparency in model reporting
- Handling sensitive datasets
- Peer-reviewed publication standards
- Case Study: Juvenile justice program evaluation
Module 14: Review of Published Studies
- Evaluating methodological quality
- Identifying misuse of models
- Understanding effect sizes
- Reproducibility concerns
- Literature matrix construction
- Case Study: Meta-analysis of workplace productivity
Module 15: Capstone Project & Presentation
- Developing your research question
- Designing multilevel models
- Running and refining models
- Creating visual outputs
- Presenting findings
- Case Study: Participant-chosen dataset
Training Methodology
- Instructor-led live sessions
- Hands-on lab assignments using real datasets
- Peer group discussion forums
- Weekly quizzes and knowledge checks
- Personalized feedback and guidance
- Final capstone project with certification
Register as a group from 3 participants for a Discount
Send us an email: info@datastatresearch.org or call +254724527104
Certification
Upon successful completion of this training, participants will be issued with a globally- recognized certificate.
Tailor-Made Course
We also offer tailor-made courses based on your needs.
Key Notes
a. The participant must be conversant with English.
b. Upon completion of training the participant will be issued with an Authorized Training Certificate
c. Course duration is flexible and the contents can be modified to fit any number of days.
d. The course fee includes facilitation training materials, 2 coffee breaks, buffet lunch and A Certificate upon successful completion of Training.
e. One-year post-training support Consultation and Coaching provided after the course.
f. Payment should be done at least a week before commence of the training, to DATASTAT CONSULTANCY LTD account, as indicated in the invoice so as to enable us prepare better for you.