Training Course on Topic Modeling and Document Clustering
Training Course on Topic Modeling & Document Clustering focuses on equipping professionals with the essential skills to analyze unstructured data, extract insights, and organize information at scale.
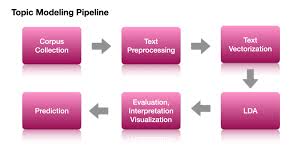
Course Overview
Training Course on Topic Modeling & Document Clustering
Introduction
In today's data-rich environment, unstructured text data represents a vast, untapped resource for gaining profound insights. Organizations across industries are grappling with overwhelming volumes of documents, from customer feedback and research papers to legal transcripts and social media conversations. Traditional manual analysis methods are simply inadequate for extracting meaningful patterns and latent themes from such massive text corpora. This training course provides a comprehensive and practical dive into Topic Modeling and Document Clustering, powerful Natural Language Processing (NLP) techniques that automate the discovery of hidden structures within textual data. By leveraging these advanced analytical tools, participants will learn to transform raw text into actionable intelligence, enabling more informed decision-making and strategic advantage.
Training Course on Topic Modeling & Document Clustering focuses on equipping professionals with the essential skills to analyze unstructured data, extract insights, and organize information at scale. We will explore various machine learning algorithms for text analysis, emphasizing hands-on application and real-world scenarios. From understanding the nuances of text preprocessing to implementing and evaluating state-of-the-art topic models and clustering algorithms, attendees will gain the expertise to unlock the true value of their textual datasets. This course is designed to empower participants to identify emerging trends, categorize content efficiently, and enhance information retrieval capabilities within their organizations.
Course Duration
5 days
Course Objectives
- Understand and apply robust techniques for cleaning and preparing unstructured text data for NLP analysis, including tokenization, stopwords removal, stemming, and lemmatization.
- Convert text into numerical representations using modern techniques like TF-IDF, Word Embeddings (Word2Vec, GloVe), and Transformer-based Embeddings (BERT, Sentence-Transformers) for machine learning.
- Learn the theoretical foundations and practical implementation of LDA, a foundational algorithm for probabilistic topic modeling.
- Investigate cutting-edge topic modeling approaches such as BERTopic, NMF (Non-Negative Matrix Factorization), and Correlated Topic Models for more nuanced topic discovery.
- Understand and implement the K-Means algorithm for grouping similar documents based on their content, analyzing document similarity.
- Learn hierarchical clustering techniques for creating nested groupings of documents, visualizing relationships through dendrograms.
- Assess the quality and interpretability of discovered topics using metrics like coherence scores and perplexity.
- Apply various metrics such as silhouette score, Dunn index, and Davies-Bouldin index to evaluate the effectiveness of document clusters.
- Create compelling visualizations (e.g., word clouds, topic-document distribution charts, cluster scatter plots) to communicate findings effectively.
- Leverage topic models and clustering to identify key entities, summarize large documents, and support information extraction.
- Integrate topic modeling with sentiment analysis to understand the emotional tone associated with specific themes and topics.
- Apply topic modeling and document clustering principles to develop basic content recommendation engines and personalized content delivery.
- Work through practical case studies to solve diverse business problems related to customer feedback analysis, content categorization, and trend detection.
Organizational Benefits
- Automatically uncover hidden patterns and themes in vast datasets, leading to improved understanding and utilization of unstructured information.
- Efficiently categorize, organize, and retrieve documents, reducing manual effort and increasing operational efficiency.
- Gain actionable insights from text data to inform strategic business decisions, product development, marketing strategies, and customer service improvements.
- Identify emerging trends, market shifts, and customer sentiments faster than competitors, enabling proactive responses and innovation.
- Automate the analysis of large text corpora, saving significant time and resources compared to manual review.
- Develop more effective content recommendation systems and personalized user experiences by understanding user interests through topic analysis.
- Detect potential issues, compliance risks, or negative sentiment early by continuously monitoring textual data.
Target Audience
- Data Scientists
- Machine Learning Engineers.
- Business Intelligence Analysts
- Market Research Professionals.
- Content Strategists/Managers.
- Researchers (Academic & Industry)
- Software Developers applications.
- Anyone Handling Large Text Corpora
Course Outline
Module 1: Introduction to Text Analytics & Unstructured Data
- Understanding the landscape of unstructured text data and its business value.
- Overview of Natural Language Processing (NLP) and its role in text analysis.
- Introduction to the core concepts of Topic Modeling and Document Clustering.
- Challenges and opportunities in working with large text corpora.
- Setting up the Python environment and essential libraries (NLTK, spaCy, scikit-learn).
- Case Study: Analyzing customer reviews from an e-commerce platform to understand the overall sentiment and identify key discussion points.
Module 2: Text Preprocessing for Robust Analysis
- Tokenization: Breaking text into meaningful units (words, sentences).
- Stopwords Removal & Punctuation Handling: Eliminating noise and irrelevant terms.
- Stemming & Lemmatization: Reducing words to their base forms for consistent analysis.
- Part-of-Speech Tagging (POS) & Named Entity Recognition (NER) basics.
- Handling special characters, numerical data, and data cleaning best practices.
- Case Study: Preprocessing a corpus of news articles to prepare them for topic extraction, demonstrating the impact of cleaning on analysis quality.
Module 3: Text Vectorization: Representing Text Numerically
- Bag-of-Words (BoW) and TF-IDF: Traditional approaches for converting text into numerical vectors.
- Understanding the limitations of sparse representations.
- Word Embeddings: Deep dive into Word2Vec and GloVe for capturing semantic relationships.
- Contextual Embeddings (Transformer-based): Introduction to BERT and Sentence-Transformers for richer semantic representations.
- Practical implementation of various vectorization techniques in Python.
- Case Study: Comparing TF-IDF and Word2Vec representations for a dataset of scientific abstracts and observing differences in similarity calculations.
Module 4: Latent Dirichlet Allocation (LDA) for Topic Modeling
- Theoretical foundation of LDA: generative probabilistic model.
- Assumptions and parameters of the LDA algorithm (number of topics).
- Implementing LDA using popular libraries (Gensim, scikit-learn).
- Interpreting LDA outputs: topic-word distributions and document-topic distributions.
- Evaluating LDA models using coherence scores.
- Case Study: Discovering latent research themes from a collection of academic papers in a specific scientific domain using LDA.
Module 5: Advanced Topic Modeling Techniques
- Non-Negative Matrix Factorization (NMF): An alternative matrix factorization approach for topic discovery.
- BERTopic: Leveraging transformer embeddings and clustering for robust topic modeling.
- Dynamic Topic Models for analyzing topic evolution over time.
- Strategies for choosing the optimal number of topics.
- Advanced techniques for topic interpretability and labeling.
- Case Study: Analyzing a time-series dataset of social media posts (e.g., Twitter data) to identify emerging and fading trends using dynamic topic models or BERTopic over time.
Module 6: Document Clustering Fundamentals (K-Means & Hierarchical)
- Introduction to unsupervised learning and clustering objectives.
- K-Means Clustering: Algorithm, strengths, weaknesses, and practical implementation.
- Determining the optimal number of clusters (Elbow Method, Silhouette Score).
- Hierarchical Clustering: Agglomerative and Divisive methods.
- Visualizing cluster relationships with dendrograms.
- Case Study: Grouping legal documents (e.g., contracts, case precedents) into relevant categories using K-Means or Hierarchical Clustering to improve document searchability.
Module 7: Advanced Document Clustering & Evaluation
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise): Clustering based on density, useful for irregular shapes.
- HDBSCAN (Hierarchical DBSCAN): Robust clustering that can handle varying densities.
- Evaluating clustering performance: Silhouette score, Davies-Bouldin index, external validation metrics (if labels available).
- Visualizing high-dimensional clusters using dimensionality reduction techniques (PCA, t-SNE, UMAP).
- Practical considerations for large-scale document clustering.
- Case Study: Clustering patient medical records or clinical notes to identify cohorts with similar conditions or treatment responses, assisting in medical research.
Module 8: Applications, Interpretation & Future Trends
- Integrating Topic Modeling and Document Clustering with other NLP tasks (e.g., sentiment analysis, text summarization).
- Building basic recommender systems based on document similarity.
- Communicating topic model and clustering insights effectively to stakeholders.
- Ethical considerations in text analytics and responsible AI.
- Current trends and future directions in NLP for text analysis (e.g., Large Language Models (LLMs) for topic generation, zero-shot topic modeling).
- Case Study: Developing a system to analyze customer support tickets, identifying recurring issues through topic modeling and routing similar tickets to specialized teams via document clustering.
Training Methodology
Our training methodology emphasizes an interactive, hands-on, and practical learning experience.
- Instructor-Led Sessions: Engaging lectures providing theoretical foundations and conceptual understanding.
- Live Coding Demonstrations: Step-by-step walkthroughs of algorithm implementation using Python.
- Hands-on Labs & Exercises: Practical coding exercises to reinforce concepts and build proficiency.
- Real-World Case Studies: Application of techniques to diverse datasets, mimicking real-world business scenarios.
- Interactive Q&A: Dedicated time for questions and discussions to clarify doubts.
- Group Discussions: Fostering collaborative learning and problem-solving.
- Project-Based Learning: A culminating project where participants apply learned skills to a comprehensive text analysis task.
- Jupyter Notebooks: All code and explanations provided in interactive Jupyter notebooks for easy reference and practice.
Register as a group from 3 participants for a Discount
Send us an email: info@datastatresearch.org or call +254724527104
Certification
Upon successful completion of this training, participants will be issued with a globally- recognized certificate.
Tailor-Made Course
We also offer tailor-made courses based on your needs.
Key Notes
a. The participant must be conversant with English.
b. Upon completion of training the participant will be issued with an Authorized Training Certificate
c. Course duration is flexible and the contents can be modified to fit any number of days.
d. The course fee includes facilitation training materials, 2 coffee breaks, buffet lunch and A Certificate upon successful completion of Training.
e. One-year post-training support Consultation and Coaching provided after the course.
f. Payment should be done at least a week before commence of the training, to DATASTAT CONSULTANCY LTD account, as indicated in the invoice so as to enable us prepare better for you.